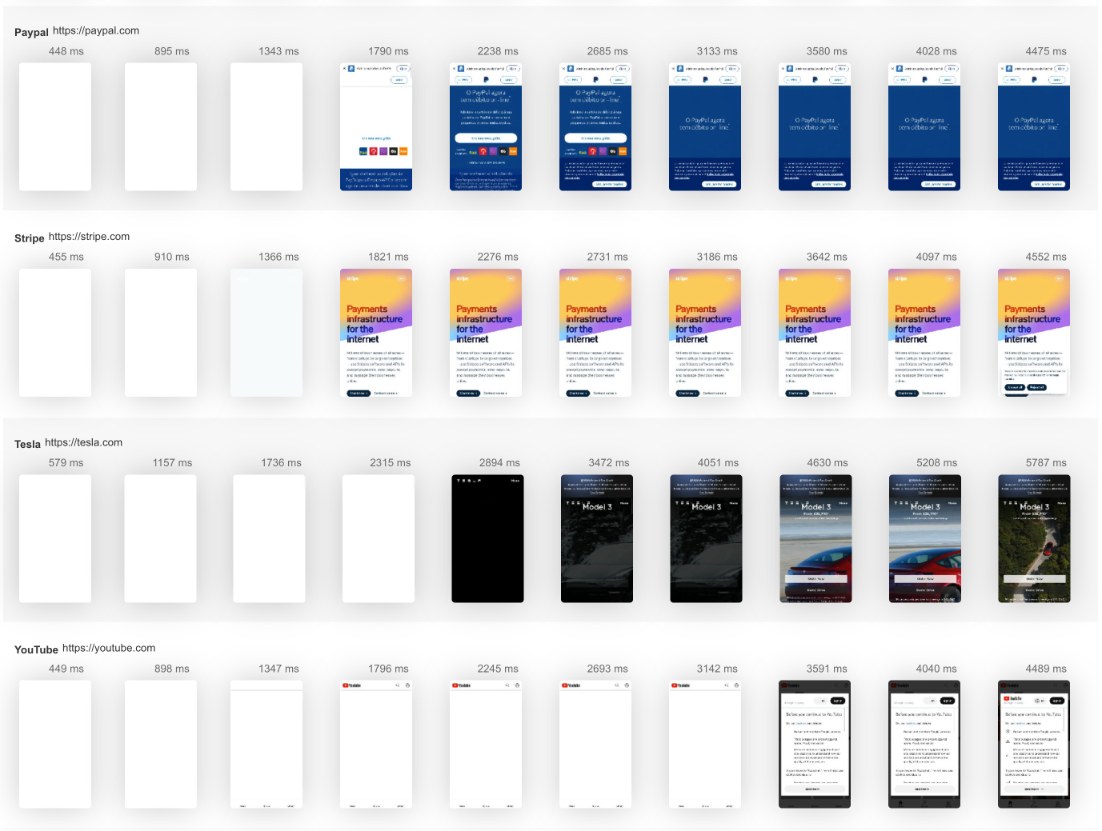
AutoPush is the complete AI content automation platform that handles keyword research, article writing, SEO optimization, and automatic publishing. Grow your organic traffic 24/7 without hiring writers or learning SEO—trusted by 10,000+ businesses.Start 7-day free trial→