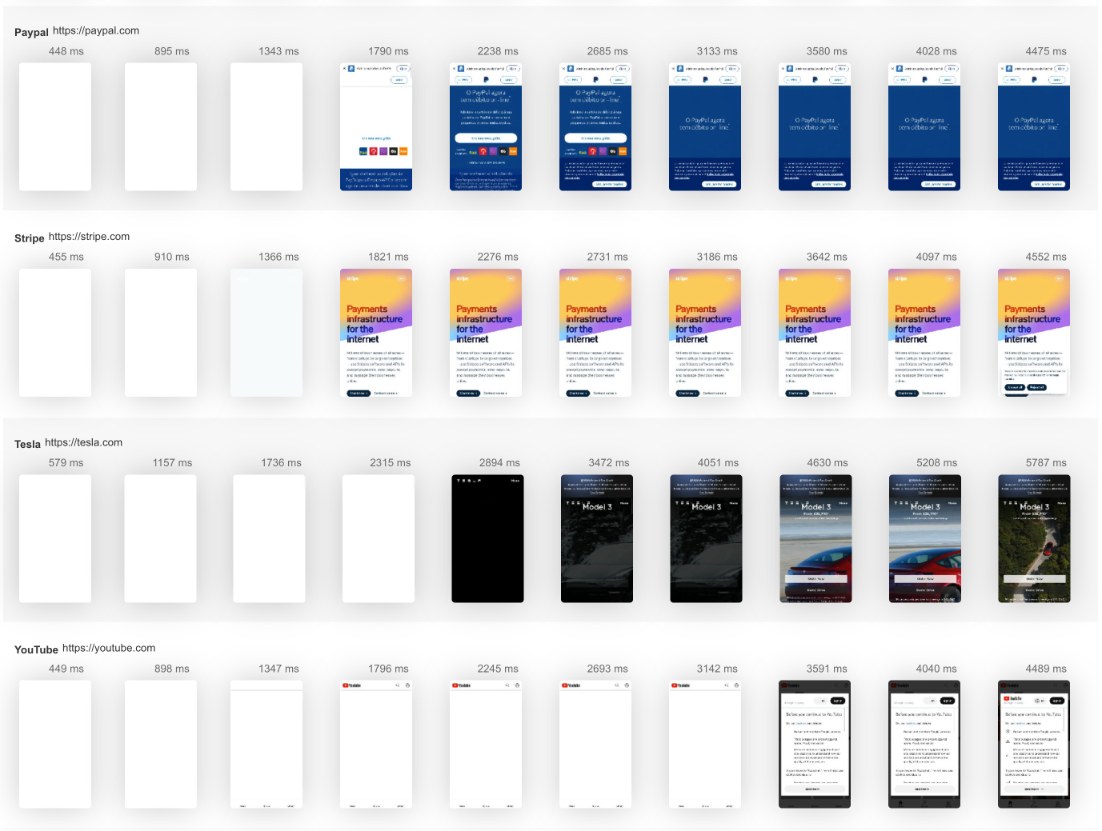
AutoPush est la plateforme complète d'automatisation de contenu par IA qui gère la recherche de mots-clés, la rédaction d'articles, l'optimisation SEO et la publication automatique. Développez votre trafic organique 24h/24 et 7j/7 sans embaucher de rédacteurs ni apprendre le SEO — approuvé par plus de 10 000 entreprises.Commencer l'essai gratuit de 7 jours→