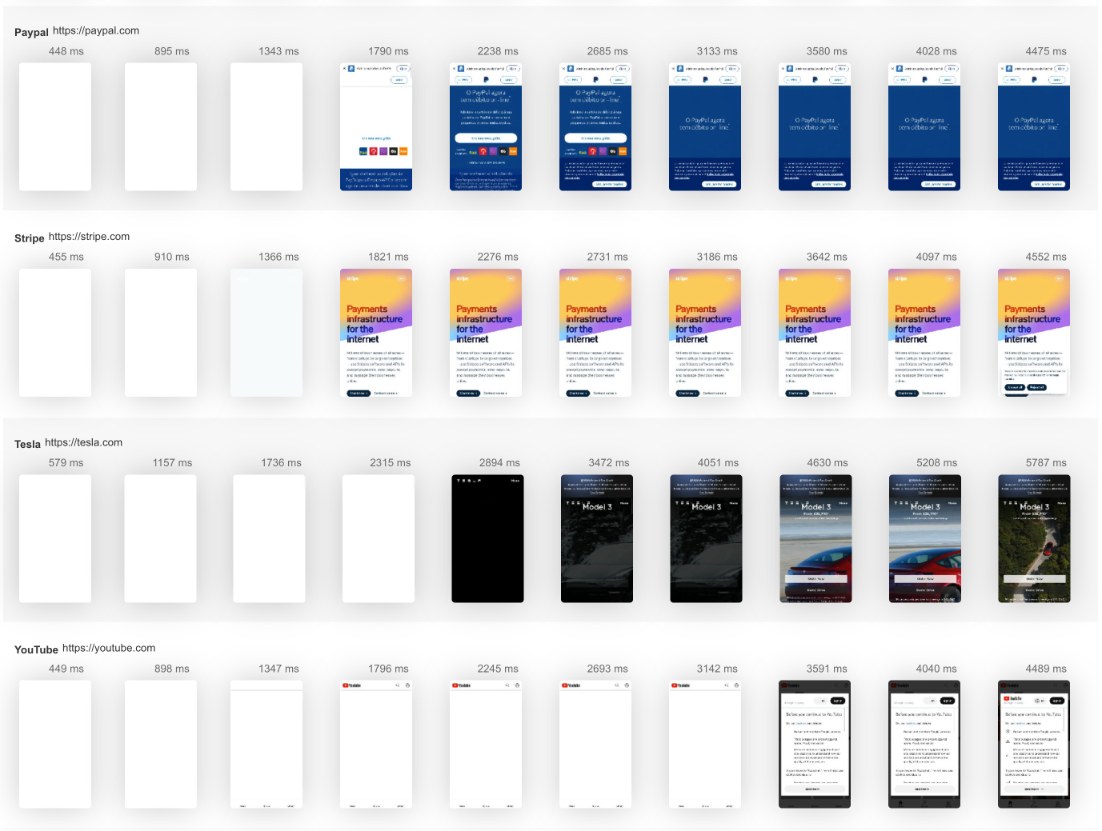
O AutoPush é a plataforma completa de automação de conteúdo com IA que trata da pesquisa de palavras-chave, escrita de artigos, otimização SEO e publicação automática. Aumente o seu tráfego orgânico 24/7 sem contratar escritores ou aprender SEO — confiança de mais de 10.000 empresas.Iniciar teste gratuito de 7 dias→